The Advantages And Disadvantages Of K-Means.
Di: Ava
Guide to K-Means Clustering Analysis and its definition. We explain its examples, formula, diagram, applications, vs K-Nearest Neighbor. The k-means cluster algorithm classifies information based on the similarities of the data points. Professionals use this method for customer segmentation, habitat classification analysis, gene expression patterns, trend identification for prediction, and more. In this article, discover more about k-means clustering, how industry leaders use this technique, its
Understanding K-means Clustering in Machine Learning
K-Means is a centroid-based clustering algorithm that partitions data into k clusters based on their distance from the mean (centroid) of each cluster. It works by randomly selecting k initial centroids, then iteratively updating them until the clusters converge. K-means clustering comes with several advantages that make it a favorite among data scientists: Simplicity: The algorithm is easy to understand and implement, even if you’re new to clustering Pros and cons means “advantages and disadvantages.” This phrase is used when carefully considering the good and bad points of something.
Disadvantagess of K-means Clustering 1. It assumes prior knowledge of the data and requires the analyst to choose the appropriate number of clusters (k) in advance. However, the K-Means algorithm has some deficiencies, such as need to pre-select the value of K, lack utilization of prior knowledge, limited interpretability This blog post provides a comprehensive overview of the KMeans clustering algorithm, detailing its steps, advantages, and disadvantages, making it a valuable resource for those interested in unsupervised learning techniques.
Learn the pros and cons of hierarchical and k-means clustering, and see how they are used in quantitative research. K-means clustering is a powerful unsupervised machine learning algorithm. It is used to solve many complex machine learning problems. K-means (or alternatively Hard C-means after introduction of soft Fuzzy C-means clustering) is a well-known clustering algorithm that partitions a given dataset into (or ) clusters.
3) What Are The Advantages Of K Means Clustering Algorithms? Relatively simple to implement Scales to large data sets Guarantees convergence Can warm-start the positions of centroids Easily adapts to new examples Generalize clusters of different shapes and sizes, such as elliptical clusters 4) What Are The Disadvantages Of K Means K-Means clustering is an unsupervised learning algorithm used for data clustering, which groups unlabeled data points into groups or clusters.
The k-nearest neighbors (KNN) algorithm is a non-parametric, supervised learning classifier, which uses proximity to make classifications or predictions about the grouping of an individual data point. It is one of the popular and simplest classification and regression classifiers used in machine learning today.
K-Means Clustering Analysis
K-means is a simple but powerful clustering algorithm in machine learning. Here, our expert explains how it works and its plusses and minuses. Common interview questions asked around k-Means such as its pros/cons, when to use it, variations of the simple k-Means, and how to code it The K-means algorithm is a machine-learning algorithm for clustering. This type of learning is unsupervised. We use K-Means to group
- K-Means Advantages and Disadvantages
- K- means clustering algorithm explained with advantages & disadvantages
- Disadvantage vs. Advantage — What’s the Difference?
- The Drawbacks of K-Means Algorithm
K-Means Clustering is an unsupervised learning algorithm that is used to solve the clustering problems in machine learning or data science. In this topic, we will learn what is K-means clustering algorithm, how the algorithm works, along with the Python implementation of k-means clustering. What is K-Means Algorithm? K-Means Clustering is an Unsupervised Projection Based Advantages and Disadvantages of K-Means Clustering Advantages: A fast, effective and efficient algorithm Easy to
The K-Truss is a structural system commonly used as a bridge structure. But what are its different members, and how does it work? Learn more in this article.

In this article we will understand a clustering algorithm by answering the following question: What is clustering? What are the real-world applications of clustering? How does K-means Clustering work? How can we find the value of K? What are the advantages and disadvantages of K-Means Clustering? How to implement K-Means Clustering? What is
K-Means Clustering is an unsupervised learning algorithm used to group data points into distinct clusters based on similarity. It’s widely applied in tasks like market segmentation, image compression, and anomaly detection, known for its simplicity, efficiency, and scalability in handling large datasets. What is K-Means Clustering? K-Means Clustering is an
DBSCAN vs. K-Means: A Guide in Python
Advantages and disadvantages are contrasting conditions, existing on opposing ends of a spectrum of favorable to unfavorable conditions. An advantage can be innate or acquired, providing an individual, group, or entity with preferential benefits or opportunities. On the other hand, a disadvantage represents inherent or acquired conditions that impose restrictions, K-means clustering is one of the most used clustering algorithms in machine learning. In this article, we will discuss the concept, examples, advantages, and disadvantages of the k-means clustering algorithm. We will also discuss a numerical on k-means clustering to understand the algorithm in a better way. What is K-means Clustering? K-means clustering is
K- means clustering algorithm explained with advantages & disadvantages #kmeans #kmeansclustering #clustering Connect with me here: Instagram : / bigdata_knowledgehunt what is clustering ? We also implemented the algorithm using its code in Python and R. Lastly, we studied about the challenges of the algorithm followed by its applications, advantages and disadvantages. You may take an overview of more machine learning algorithms here. Machine Learning Certifications Machine Learning Books Machine Learning Interview Guide to the Nearest Neighbors Algorithm. Here we discuss the classification, implementation along with advantages and disadvantages.
K-Means algorithm is an unsupervised clustering algorithm, it is relatively simple to implement and the clustering effect is also good, so it is widely used. There are a large number of variants of the K-Means algorithm. This article starts with the most traditional K-Means algorithm, and on its basis, describes the optimization variant method of K-Means. Including initialization 18.1 History of the k-means algorithm The k-means clustering algorithm was first proposed by Stuart Lloyd in 1957 as a technique for pulse-code modulation. However, it was not published until 1982. In 1965, Edward W. Forgy published an essentially identical method, which became widely known as the k-means algorithm. Since then, k-means clustering has become
We have also discussed the advantages and disadvantages of K-maps and some related graphical methods that can be used for similar purposes. K-maps are a useful technique for designing digital logic circuits with a small number of input variables, as they can reduce the complexity of Boolean expressions without requiring complex K-Means is a popular unsupervised machine learning algorithm used for clustering tasks. It groups similar data points together into clusters based on their feature similarity, without any prior knowledge of the groups.
KMeans Explained, Practical Guide & How To In Python
I have researched that K-medoid Algorithm (PAM) is a parition-based clustering algorithm and a variant of K-means algorithm. It has solved the problems of K-means like producing empty clusters and
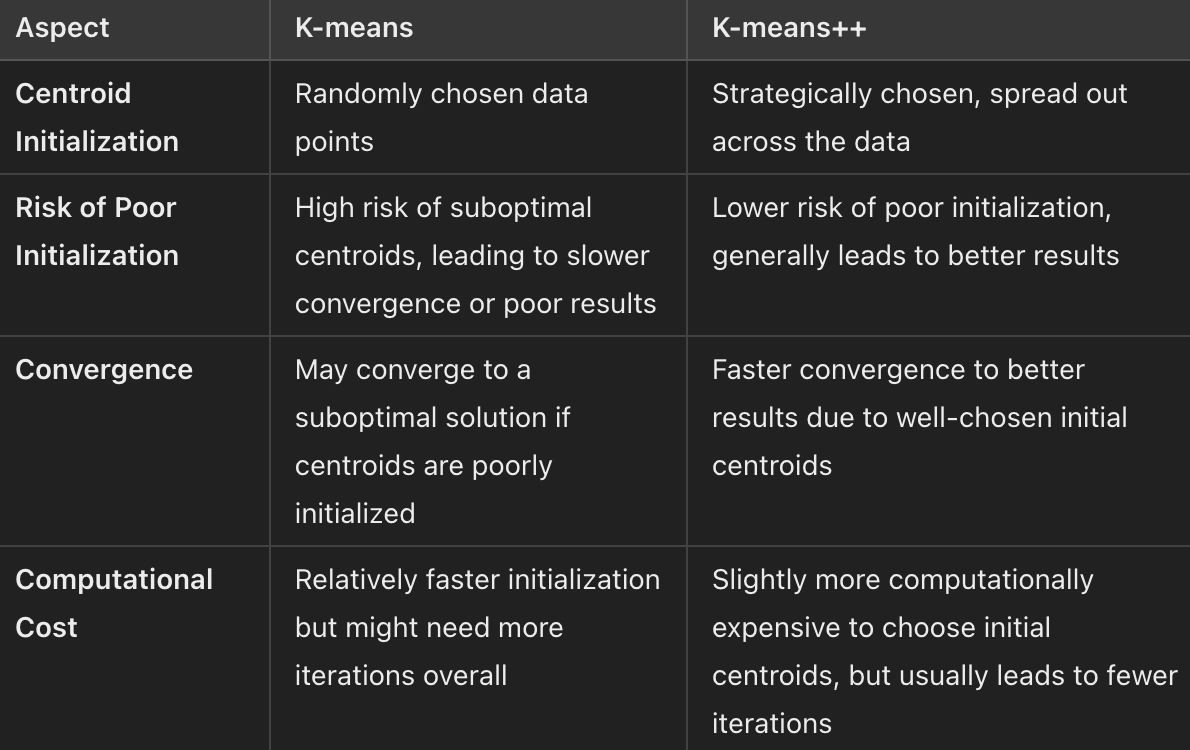
Note: Although the initialization in K-means++ is computationally more expensive than the standard K-means algorithm, the run-time for convergence to optimum is drastically reduced for K-means++. Can someone explain the pros and cons of Hierarchical Clustering? Does Hierarchical Clustering have the same drawbacks as K
- The Basic Body Shape Of Fish And How They Move
- The 5 Data Consolidation Patterns
- The Acaf Customer Feedback Loop
- The 5 Best All Inclusive Resorts In Nevada
- The 30 Best Places To Visit In Fort Kochi
- The Ad-Based Internet Is About To Collapse. What Comes Next?
- The Atomic Clock, Invented In 1948, Paved The Way For Gps
- The 800 Calorie Diet Study | What is the Fast 800 diet?
- The Benefits And Power Of Assisted Natural Regeneration
- The 17 Best Boutique Hotels In Southampton
- The 7 Best Wireless Earbuds For Android
- The Balkan Foodie : Mamas hausgemachter Ajvar 550g mild
- The 2012 Briganti Nomogram Predicts Disease Progression In
- The Benefits Of Drinking Italian Wine