Spark And Kafka In Docker Cluster
Di: Ava
Hence we want to build the Real Time Data Pipeline Using Apache Kafka, Apache Spark, Hadoop, PostgreSQL, Django and Flexmonster on Docker to generate insights out of this data. The Spark Project/Data Pipeline is built using Apache Spark with Scala and PySpark on Apache Hadoop Cluster which is on top of Docker. Explore the Apache Kafka Docker image for efficient event-driven applications with faster startup, lower memory usage, and helpful management scripts.
Real-Time Analytics: By integrating Kafka with PySpark, you gain the ability to process data in real time as it’s ingested, allowing for timely insights and decisions. Scalability: Both Kafka and PySpark are designed to scale horizontally. Kafka distributes the workload across multiple partitions, and PySpark parallelizes data processing tasks across a cluster of nodes. In this end-to-end guide, I’ll show you how to run a Kafka Cluster along with a Kafka producer application in Docker. We’ll start from scratch and finish with a fully working setup where your Apache Spark and Apache Kafka are two powerful big data tools that can be combined to create scalable, real-time data processing pipelines.
Be aware that the default minikube configuration is not enough for running Spark applications. We recommend 3 CPUs and 4g of memory to be able to start a simple Spark application with a single executor. Check kubernetes-client library ’s version of your Spark environment, and its compatibility with your Kubernetes cluster’s version. Each service, be it Kafka, Spark, or Airflow, runs in its isolated environment, thanks to Docker containers. This not only ensures smooth With the rise of containerization, running Kafka with Docker and Docker Compose has become a popular and efficient method for deploying Kafka clusters. In this tutorial, we will go step-by-step to set up Kafka alongside Zookeeper using Docker and Docker Compose, and then we’ll explore how to interact with your Kafka cluster.
Exposing Kafka Service Through Port-Forwarding Proxy
The docker-compose.yaml file specifies the Kafka services and includes a docker-proxy. This proxy is essential for executing Spark jobs through a docker-operator in Airflow, a concept that will be elaborated on later. The spark directory contains a custom Dockerfile for spark setup. src contains the python modules needed to run the
In this tutorial, learn how to run a Kafka broker locally on your laptop, with step-by-step instructions and supporting code. Learn to build a data engineering system with Kafka, Spark, Airflow, Postgres, and Docker. This tutorial offers a step-by-step guide to building a complete pipeline using real-world data, ideal for beginners interested in practical data engineering applications. Apache Kafka, a distributed event streaming platform, is often at the heart of these architectures. Unfortunately, setting up and deploying your own Kafka instance for development is often tricky. Fortunately, Docker and containers make this much easier. In this guide, you will learn how to: Use Docker to launch up a Kafka cluster Connect a non-containerized app to the cluster
We wrote about this architecture in an earlier post, Spark Structured Streaming With Kafka and MinIO, demonstrating how to leverage its unified batch and streaming API to create a dataframe from data published to Kafka. This architecture alleviates the burden of optimizing the low level elements of streaming and provides end-to-end functionality. Kafka
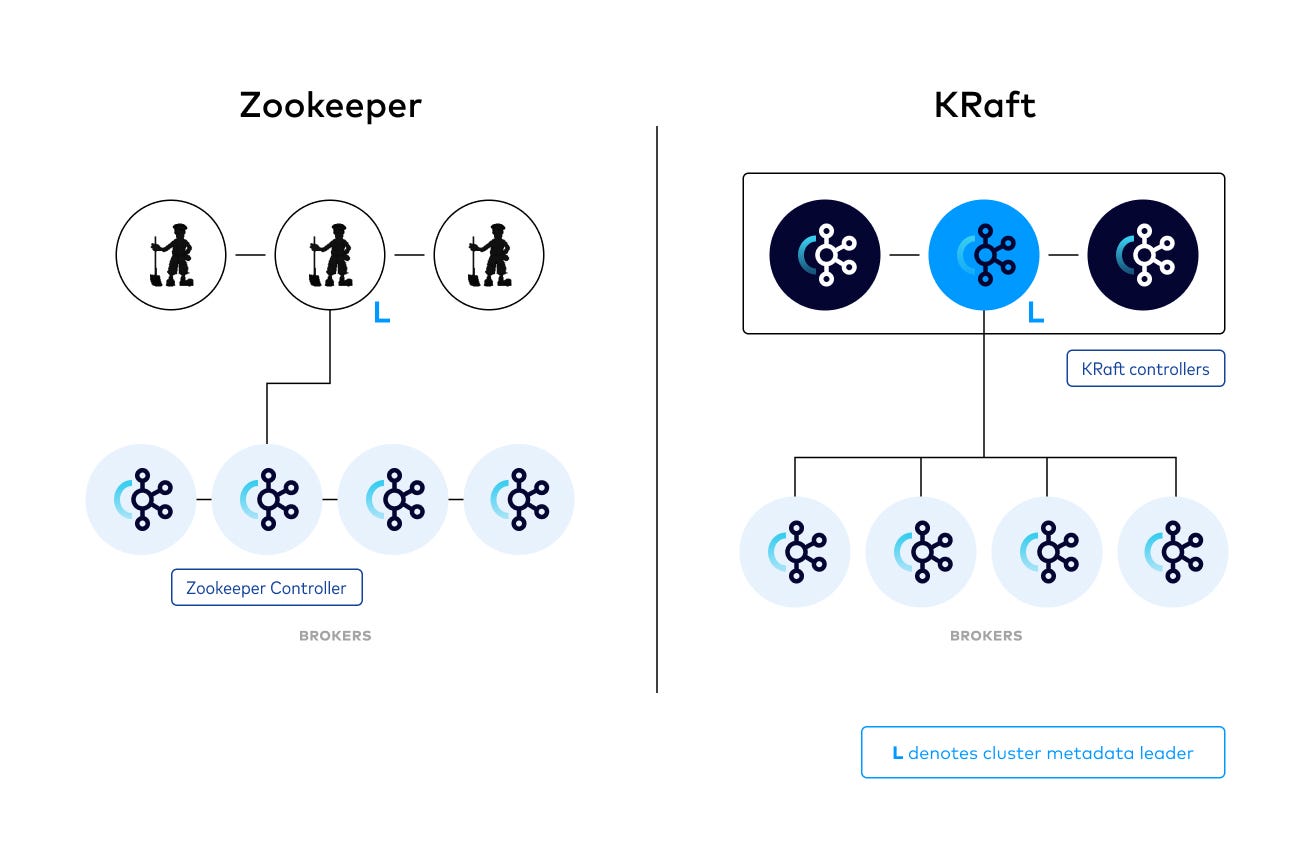
Step-by-step guide to deploying an ETL process analyzing tweets sentiment in real-time with Docker, Apache Kafka, Spark Streaming, MongoDB and Delta Lake A working Docker setup that runs Hadoop and other big data components is extremely useful for development and testing. However, finding a simple yet fully functional setup can be challenging. Docker Services: – Zookeeper*: Coordinates Kafka brokers and stores cluster metadata. – Kafka Broker: Manages data streaming and storage.
Bitnami’s Docker image for Apache Spark offers a reliable and efficient solution for data engineering, science, and machine learning on various platforms.
- Stream processing with Apache Kafka and
- Exposing Kafka Service Through Port-Forwarding Proxy
- Guide to Setting Up Apache Kafka Using Docker
- How to Integrate Kafka with PySpark: A Step-by-Step Guide
First of all, please visit my repo to be able to understand the whole process better. This project will illustrate a streaming data The Kafka cluster stores streams of records in categories called topics. See my other blog for installation and starting a kafka service Kafka and Zookeeper with Docker.
Running Kafka and a Producer App in Docker: A Practical Guide
Today, there are many projects available that were created to deploy a Spark or Hadoop cluster, but they are either ineffective or resource-intensive, causing the system to freeze. This repository is created to simplify the deployment of these clusters on Spark This guide will get you up and running with Apache Iceberg™ using Apache Spark™, including sample code to highlight some powerful features. You can learn more about Iceberg’s Spark runtime by checking out the Spark section. Docker-Compose Creating a table Writing Data to a Table Reading Data from a Table Adding A Catalog Next Steps Docker-Compose The
Custom Spark-Kafka Cluster This project sets up a custom Spark-Kafka cluster using Docker and Docker Compose. It includes Apache Spark, Apache Kafka, PostgreSQL, Hive Metastore, LocalStack for S3, Prometheus, and Grafana. Learn how to set up a fully configured, multi-node Spark cluster locally using DevContainer with Docker Compose. Ready out-of-the-box, immediately start coding with zero configuration needed — perfect for data engineering and PySpark development. Producer: is a Kafka Producer that produces fake data about an user information using Java Faker and produce messages onto Kafka. Kafka
It turns out you can copy paste services from the Spark docker-compose.yml to the Hadoop docker-compose.yml, provided that I added the directories provided in the docker-spark Github repository. This project involves creating a real-time ETL (Extract, Transform, Load) data pipeline using Apache Airflow, Kafka, Spark, and Minio S3 for This project is a real-time data pipeline designed for ingesting, processing, and storing telecom call records. It integrates Apache Kafka, Apache Spark Streaming, and AWS Redshift to handle large volumes of streaming data in near real-time. The pipeline is containerized with Docker Compose, enabling easy deployment, scalability, and modularity.
Big data playground: Cluster with Hadoop, Hive, Spark, Zeppelin and Livy via Docker-compose. I wanted to have the ability to play around with various big data applications as effortlessly as possible, namely those found in Amazon EMR. Ideally, that would be something that can be brought up and torn
Hadoop is an open source distributed framework that manages data processing and storage for big data applications in clustered systems I’ve created a Spark cluster with one master and two slaves, each one on a Docker container. I launch it with the command start-all.sh. I can reach the UI from my local machine at localhost:8080 an This tutorial will guide you through setting up a Kafka cluster with three brokers and a Kafka UI for easy monitoring, all using Docker Desktop. The Docker Compose file provided includes
Apache Spark is the popular distributed computation environment. It is written in Scala, however you can also interface it from Python. For those who want to Introduction In today’s fast-paced world, businesses need to process and analyze data in real time to stay competitive. Real-time data
archie-cm/docker-hadoop-bigdata
- Spaß Aktivator Spiel Für Ultimativen Genuss
- Soñar Con Serpiente Atacando: ¿Qué Significados?
- Spaziergang Im Feld In Schwerte
- Sparkasse An Volme Und Ruhr, Vermögensmanagement Lüdenscheid
- Spedition Heilbronn: Ab 19 € _ Karriere / christ Karriere
- Spark 2.9.2 Released
- Spdr S – Spdr S&P 500 , SPDR S&P Euro Dividend Aristocrats UCITS ETF
- Spar Gourmet In Wien, Döblinger Hauptstraße 80
- Sozialticket Ist Gebot Der Stunde
- Specials Meerlust Auf Spiekeroog
- Speaking Soviet With An Accent: Culture And Power In Kyrgyzstan
- Spanisch: Por Und Para: Por Oder Para Regeln
- Spa 2000: Wie Häkkinen Schumacher Spektakulär Überholte
- Spaghettis À La Sauce Tomate _ La meilleure sauce à spaghetti au monde : Le secret d’une bonne sauce
- Sparkasse Beratungscenter Eberstadt