Large-Scale Dataset Pruning With Dynamic Uncertainty
Di: Ava
PDF | The rapid growth of dataset scales has been a key driver in advancing deep learning research. However, as dataset scale increases, the training | Find, read and This paper investigates how to prune the large-scale datasets, and thus produce an informative subset for training sophisticated deep models with negligible performance drop,
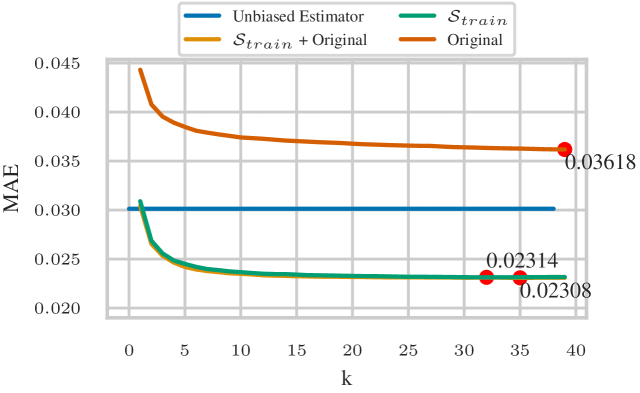
Dataset pruning aims to alleviate this demand by discarding redundant ex- amples. However, many existing methods require training a model with a full dataset over a large number of
Comparison of dataset pruning methods.
The state of the art of many learning tasks, e.g., image classification, is advanced by collecting larger datasets and then training larger models on them. As the outcome, the increasing Large-scale Dataset Pruning with Dynamic Uncertainty Muyang He, Shuo Yang, Tiejun Huang, Recent progress in AI is largely driven by large training datasets. Yet, the vast volume of training data poses substantial computational and efficiency challenges, which
Readers are encouraged to critically evaluate the method and its limitations, and to consider how it might be extended or improved upon in future studies. Conclusion The paper
In this paper, we investigate how to prune the large-scale datasets, and thus produce an informative subset for training sophisticated deep models with negligible Large-scale dataset pruning with dynamic uncertainty. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024 – Workshops, Seattle, WA, USA,
The state of the art of many learning tasks, e.g., image classification, is advanced by collecting larger datasets and then training larger models on them. As the Bibliographic details on Large-scale Dataset Pruning with Dynamic Uncertainty. Furthermore, we introduce Dynamic Data Pruning for ASR (DDP-ASR), which offers sev- eral ne-grained pruning granularities specically tailored for speech-related datasets, going beyond the
- TOWARDS ROBUST DATA PRUNING
- Data Pruning in Generative Diffusion Models
- Large-scale Dataset Pruning with Dynamic Uncertainty
In this paper, we investigate how to prune the large-scale datasets, and thus produce an informative subset for training sophisticated deep models with negligible performance drop. We ABSTRACT In the era of exceptionally data-hungry models, careful selection of the training data is essential to mitigate the extensive costs of deep learning. Data pruning of-fers a solution by It is known that large-scale datasets have much redundant and easy samples which contribute little to model training. Dataset pruning (or coreset selection) [5, 31, 14, 32, 37, 13, 33, 15, 41,
Dataset Pruning: Reducing Training Data by Examining Generalization Influence, https://arxiv.org/abs/2205.09329 Large-scale Dataset Pruning with Dynamic Uncertainty, This paper investigates how to prune the large-scale datasets, and thus produce an informative subset for training sophisticated deep models with negligible performance drop, and proposes
A growing body of literature recognizes the immense scale of modern deep learning (DL) [3, 12], both in model complexity and dataset size. The DL training paradigm
Professor, Harbin Institute of Technology (Shenzhen) – Cited by 2,093 – Data-Centric AI – Trustworthy AI – Machine Learning – Computer Vision In this paper, we investigate how to prune the large- scale datasets, and thus produce an informative subset for training sophisticated deep models with negligible perfor- mance drop. 1. Introduction A growing body of literature recognizes the immense scale of modern deep learning (DL) [3, 12], both in model complexity and dataset size. The DL training paradigm uti
Abstract Modern deep models are trained on large real-world datasets, where data quality varies and re-dundancy is common. Data-centric approaches such as dataset pruning have shown In this paper, we investigate how to prune the large- scale datasets, and thus produce an informative subset for training sophisticated deep models with negligible perfor- mance drop. This paper improves upon existing data pruning methods for image classification by introducing a novel pruning metric and pruning procedure based on importance sampling.
The state of the art of many learning tasks, e.g., image classification, is advanced by collecting larger datasets and then training larger models on them. As the outcome, the increasing
While data pruning and active learning are prominent research topics in deep learning, they are as of now largely unexplored in the adversarial training literature. We About Pruning of MNIST according to „Large-scale Dataset Pruning with Dynamic Uncertainty“
The great success of deep learning heavily relies on increasingly larger training data, which comes at a price of huge computational and infrastructural costs. This poses
In this paper, we investigate how to prune the large-scale datasets, and thus produce an informative subset for training sophisticated deep models with negligible perfor-mance drop. 3 Methods In this section, we describe our approach to data pruning. First, we re-frame data pruning as a dynamic decision making process. Next, we present our scoring mechanism
This paper investigates how to prune the large-scale datasets, and thus produce an informative subset for training sophisticated deep models with negligible While data pruning and active learning are prominent research topics in deep learning, they are as of now largely unexplored in the adversarial training literature. We
The state of the art of many learning tasks, e.g., image classification, is advanced by collecting larger datasets and then training larger models on them. As the outcome, the The state of the art of many learning tasks, e.g., image classification, is advanced by collecting larger datasets and then training larger models on them. As the outcome, the increasing The state of the art of many learning tasks, e.g., image classification, is advanced by collecting larger datasets and then training larger models on them. As the outcome, the increasing
We propose a novel method to scale data pruning for large datasets, enabling adversarial training with extensive syn-thetic data. Our approach shows that data importance can be extrapolated
- Landtechnik Top Agrar Hecken Schneiden Mit System
- Lasagne Mit No-Muh, Pesto : Lasagne mit Pesto Genovese und Hähnchenbrust
- Lara’S Diner, Dettelbach, Restaurant
- Langzeitprognosen Für Das Nigeria Wetter
- Lanz Robert Friseursalon In Neunkirchen A.Brand ⇒ In Das Örtliche
- Las Mejores 200 Ideas De Comida Para Cumpleaños
- Las 10 Ciudades De Estados Unidos Donde Viven Más Mexicanos
- Langen Nach Sprendlingen Per Zug, Linie 630 Bus, Bus, Taxi
- Laptop Samsung Can Not Install Windows 10
- Laptop Knackt Komisch _ Huawei Matebook X Pro 2020 Knackt komisch