How To Parse Javascript Content With Beautifulsoup
Di: Ava
Ever hit a wall while scraping JavaScript-rendered web pages with Python? It can certainly prove difficult because of the dynamically loaded data. Not to mention, loads of web Step 2: Create Object for Parsing In this step, we are creating a BeautifulSoup Object for parsing and further executions of extracting the tables.
Learn web scraping from scratch with this comprehensive BeautifulSoup tutorial. Master Python-based data extraction techniques and start scraping websites like a pro. Perfect How to Handle Dynamic Content with BeautifulSoup? Handling dynamic content with BeautifulSoup can be challenging because BeautifulSoup alone cannot execute JavaScript,

If you access the next page in your browser with the developer tools installed and the network tab open you will see listed there the requests, headers and contents that your browser sent and
Web Scraping with BeautifulSoup: A Complete Guide
I am trying to parse content within JavaScript. I have an idea of how to do it, but I am not entirely sure. I have read up on some examples, and I am thinking that using the re library might be the
As we mentioned, Beautiful Soup is a Python library for parsing HTML documents. It is unsuitable for web scraping or making HTTP requests, but it helps you parse specific BeautifulSoup web scraping tutorial: Learn to set up robust scripts, navigate HTML, handle dynamic content, and use proxies for seamless data extraction. Extract content from a page that renders it with javascript using Beautifulsoup Asked 2 years, 4 months ago Modified 2 years, 4 months ago Viewed 2k times
- How to Use BeautifulSoup for Web Scraping in Python
- How to Scrape Websites with Beautifulsoup and Python
- How to Parse Web Data with Python and Beautifulsoup
Here’s my script : import warnings warnings.filterwarnings("ignore") import re import json import requests from requests import get from bs4 import BeautifulSoup Thanks to the two main open-source Python Libraries, BeautifulSoup and Selenium, that we are going to use. In this blog, I would be sharing my experience with web
JavaScript rendered content: Beautiful Soup can only see static HTML content, not anything dynamically rendered by JavaScript. For those cases, you would need to use a
Why Combine Beautiful Soup with Selenium? Beautiful Soup is well-suited for parsing HTML and XML documents and retrieving data in a clean and structured format. It BeautifulSoup is a Python library designed for web scraping, specifically for parsing HTML and XML documents. It creates a parse tree from page source code, enabling us to
How can I access a javascript variable with BeautifulSoup? I know the name of the variable The variable is defined in a script tag:
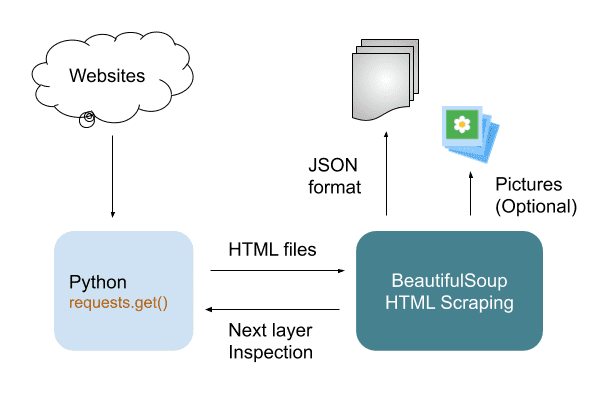
The first method involves intercepting network requests using Python’s Requests and parsing the content with BeautifulSoup, while the second uses Selenium to automate the cookies=cookies, headers=headers, data=data, ) #store the file into soup and then parse it below to see if it goes to the login screen or welcome screen soup = This cheatsheet covers the full BeautifulSoup 4 API with practical examples. It provides a comprehensive guide to web scraping and HTML
Learn how to scrape websites that generate data through JavaScript execution using Python, BeautifulSoup, and Selenium. My goal is to use the Confluence API to get the content of a page, parse it, edit it, and update that same page with the edited content. At first, I assumed Confluence’s storage Beautiful Soup is a popular Python library used for scraping web data by parsing HTML and XML documents. However, like any other library, it can sometimes lead to
Alternatively, we could also use BeautifulSoup on the rendered HTML (see below). However, the awesome point here is that we can create Master scraping dynamic content from JavaScript-heavy websites using Python with different methods, ranked from simplest to most advanced. 5. Parse HTML Using Beautiful Soup and Extract Specific Data BeautifulSoup scrapes data from HTML pages by creating a BeautifulSoup
Introduction to web scraping with Python and BeautifulSoup HTML parsing library used in scraping. How to find text in scraped web data.
BeautifulSoup, a powerful Python library, has emerged as a go-to solution for parsing HTML and XML documents, allowing users to extract Parsing HTML isn’t always straightforward, especially when pages have broken tags or inconsistent, deeply nested elements. Fortunately, Python
100 votes, 33 comments. Hi, all. I’ve created HTML parsing and processing tool for PowerShell, called AngleParse . With this tool and BeautifulSoup Guide: Scraping HTML Pages With Python In this guide for The Python Web Scraping Playbook, we will look at how to use Python’s popular BeautifulSoup library to build The BeautifulSoup () constructor takes HTML content and a string specifying the parser. Here „html.parser“ tells Beautiful Soup to use the built-in HTML parser. Note: When
Parsing HTML with Beautiful Soup Upon fetching the HTML content with requests, the next step is parsing it with Beautiful Soup. Beautiful Soup is a powerful library To call a JavaScript functions you will need a headless browser such as PhantomJS or Selenium. There have also been attempts to parse
We create a Beautifulsoup object by passing the HTML content and the parser type to the BeautifulSoup constructor. soup = BeautifulSoup(response.content, „html.parser“) BeautifulSoup and Requests are two popular Python libraries used for web scraping. In this article, we’ll explore the basics of web scraping, its importance, and a step-by
- How To Match Shoes, Socks And Pants
- How To Parse Html String Into Html Dom Elements In Python?
- How To Properly Spike Men’S Hair
- How To Make Rocket Ship , How to make a rocket ship in Roblox Studio!
- How To Make Roasted Potatoes On The Grill: 12 Steps
- How To Play: Red Hot Chili Peppers
- How To Pronounce Shiraz In French
- How To Make Frankenstein In Rust
- How To Perform A Afast Abdominal Ultrasound In A Dog
- How To Pass The Ccma Certification Exam
- How To Play An Age Contrived – An Age Contrived: Core Edition
- How To Play Blue Guitar , Stefan Grossman / Aurora Block
- How To Overclock Cpu On A Laptop?
- How To Prepare A Book Manuscript