Distributed Data Processing With Ray Data And Minio
Di: Ava
大模型推理引擎 vLLM 基于 Ray Core 及 Ray Serve 构建分布式推理能力,进一步丰富了 Ray 的 AI 生态。 2024 年,Ray 发布了 Ray 2.32 版本,引入 Ray DAG,更好地支持 AI 场景下异构设备间的通信,持续推动 Ray 在分布式计算尤其是 AI 领域的应用和发展。 How Ray Data enables distributed data processing Optimizing performance across CPUs and GPUs Hands-on session with real-world datasets 2. Ray Data: LLMs (April 30) In this webinar, we’ll cover: New APIs in Ray Data optimizing for throughput for batch LLM inference Scaling inference pipelines efficiently Managing distributed MinIO’s object storage solution, paired with AMD processors and accelerators, enables healthcare organizations to store and process massive amounts of unstructured data, ensuring that AI/ML models can be trained and deployed effectively.
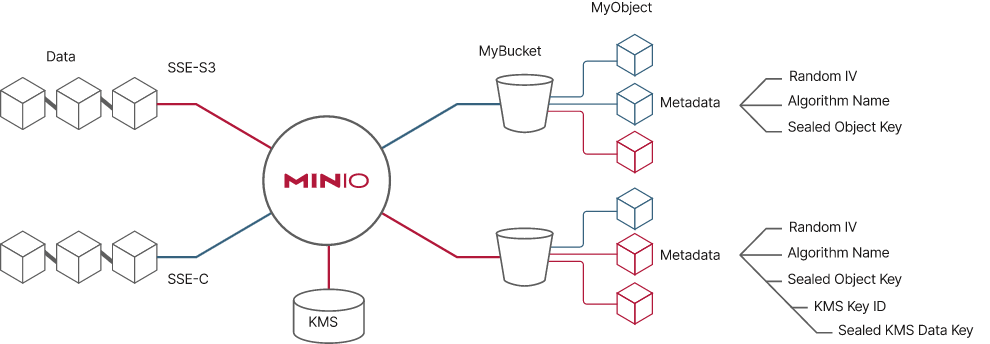
By leveraging MinIO, businesses can build a robust and scalable infrastructure to support their Big Data needs. In this guide, we will explore how to effectively utilize MinIO for scalable object storage in Big Data, outlining the benefits and best practices for implementing this powerful tool in data-intensive environments.
AIStor supports deploying resources onto Linux infrastructures and provides packages for Red Hat Enterprise Linux and Ubuntu Server platforms. Setting up AIStor on Linux involves three steps: Installing AIStor Setting up network encryption Setting up server-side encryption Minio with Apache Flink Apache Flink supports three different data targets in its typical processing flow — data source, sink and checkpoint target. While data source and sink are fairly obvious, checkpoint target is used to persist states at certain intervals, during processing, to guard against data loss and recover consistently from a failure of nodes.
Stream processing with Apache Flink and MinIO
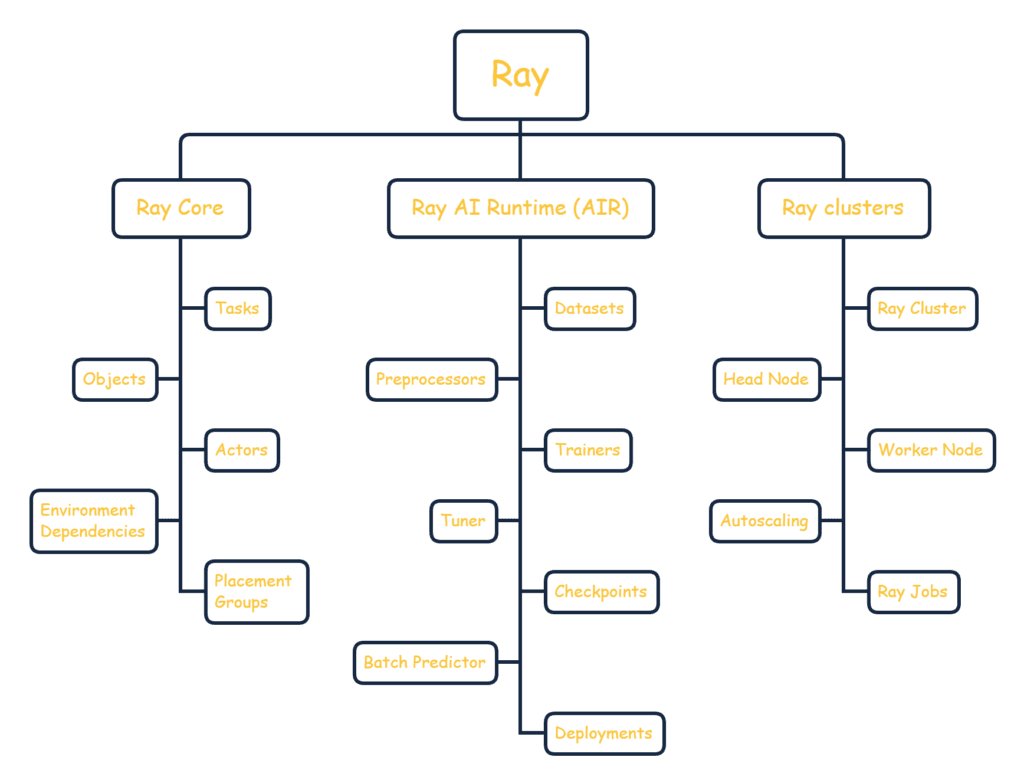
Chapter 6, Data Processing with Ray Introduces you to the Dataset abstraction of Ray and how it fits into the landscape of other data structures. You will also learn how to bring pandas data frames, Dask data structures and Apache Spark workloads to Ray.
Abstract Distributed File Systems (DFS) are essential for managing vast datasets across multiple servers, offering benefits in scalability, fault tolerance, and data accessibility. This paper presents a comprehensive evaluation of three prominent DFSs—Google File System (GFS), Hadoop Distributed File System (HDFS), and MinIO—focusing on their fault tolerance
This post is a technical post summarizing my experience with the Ray library for distributed data processing and showcasing an example of
Building a petabyte-scale data lake on MinIO with Hudi ensures scalability, fast queries, and high availability. By following best practices in partitioning, replication, and security, you get a cost-efficient, high-performance data lake that can handle massive workloads.
The distributed MinIO cluster’s fault tolerance aligns with our disaster recovery and uptime goals, helping protect the organization from data loss or prolonged downtime.
149K subscribers in the dataengineering community. News & discussion on Data Engineering topics, including but not limited to: data pipelines MinIO for Cloud-Native Data Lakes MinIO is a high-performance, distributed object storage system designed for cloud-native applications. The combination of scalability and high-performance puts every workload, no matter how demanding, within reach. MinIO has created a comprehensive blueprint for data infrastructure to support exascale AI and other large scale Conclusion Our data needs are growing rapidly, so it is critical that our genomic data processing solution is performant, scalable, and cost
Scalable Genomics Data Process Pipeline
Deduplication # Data-Juicer provides an optimized MinHash-LSH-based deduplication operator in Ray mode. It’s a multiprocessing Union-Find set in
A distributed pipeline for generating and processing PDFs using Apache Flink and Apache Kafka. Learning Ray – Flexible Distributed Python for Machine Learning
There has been a lot of buss around DeepSeek (R1) and their Open Source mission, and lately they released their full stack to train State-of-the-Art LLM’s. One of the tools is a Distributed Data Processing framework named “smallpond” built on top of DuckDB & Ray. Mike made an excellent write-up on his blog. The summary? It’s a tool that you can’t even buy with Stephen Pu, Staff Software Engineer at Alluxio, has over 15 years of experience in software R&D for data centers and distributed storage systems. He has been involved in the core product development and design of large-scale distributed data platforms at IBM, HPE, and Fortinet. # Weather Data Service with MinIO, FastAPI, and Zarr A prototype service demonstrating distributed storage and querying of meteorological data using modern technology stack.
Why Ray? The AI Challenge AI grows more complex by the hour, with complex data modalities and new models, frameworks, and accelerators released daily. Without effective infrastructure, teams face slow time to production, underutilized resources, and exploding costs. To deliver real ROI and combat the AI Complexity Wall, teams need an engine to support any workload –
Ray Datasets – our own Ray library for data processing in ML pipelines, namely data loading, preprocessing, ingestion into distributed trainers, and parallel batch inference. In today’s data-driven landscape, efficient data management and processing are crucial for deriving actionable insights. This project leverages the capabilities of AWS Glue, Jupyter Notebooks Are you looking for a practical, reproducible way to take a machine learning (ML) project from raw data all the way to a deployed, production-ready model? This post provides a blueprint for the AI/ML lifecycle, demonstrating how to use Red Hat OpenShift AI to build a workflow you can adapt to your own projects. We’ll walk through the entire machine learning
How to use Ray Data for ML pipeline
Over the past few months, I have written about a number of different technologies (Ray Data, Ray Train, and MLflow). I thought it would make sense to pull them all together and deliver an easy-to-understand recipe for distributed data preprocessing and distributed training using a production-ready MLOPs tool for tracking and model By leveraging Alluxio, Mesos, Minio, and Spark we have created an end-to-end data processing solution that is performant, scalable, and cost optimal. We use Alluxio as the unified storage layer to connect disparate storage systems and bring memory performance, with Minio mounted as the under store to Alluxio to keep cold (infrequently accessed
Distributed computing frameworks play a crucial role in data engineering by enabling the processing and analysis of large-scale data sets across multiple machines or nodes in a cluster. They provide a scalable and efficient way to handle big data workloads that cannot be effectively processed by a single machine. Distributed computing frameworks enable scalable, Implementation There are many frameworks for distributed computing, such as Ray, Dask, Modin, Spark, etc. All of these are great options but for our application we want to choose a framework that is will allow us to scale our data processing operations with minimal changes to our existing code and all in Python.
In summary, Hadoop and Minio differ in terms of their scalability approach, distributed file system, data processing paradigm, compatibility, data consistency guarantees, and ease of deployment and management. Want real-time analytics and blazing-fast performance? Learn how to build a high-speed, on-prem pipeline with Materialize and MinIO A Dataset is a distributed data collection for data loading and processing. Datasets are distributed pipelines that produce ObjectRef [Block] outputs, where each block holds data in Arrow format, representing a shard of the overall data collection. The block also determines the unit of parallelism. For more details, see Ray Data Key Concepts.
In the era of distributed data and machine learning, traditional Python scripts often struggle to scale. This is where Ray shines — a In this article, we will walk through the process of setting up a real-time data processing and analytics environment for vehicle plate recognition. We will use Docker to manage our services, MySQL for data storage, Redpanda as a streaming platform, MinIO as an object storage server, and Apache Spark for data processing and analysis. RayDP brings popular big data frameworks including Apache Spark to Ray ecosystem and integrates with other Ray libraries seamlessly. RayDP makes it simple to build distributed end-to-end data analytics and AI pipeline on Ray by using Spark for data preprocessing, RayTune for hyperparameter tunning, RaySGD for distributed deep learning, RLlib for reinforcement
Data Loading and Preprocessing — Ray 2.49.1
- Djh-Jugendherberge Born-Ibenhorst Mit Zeltplatz • Campingplatz
- Dispensa Eletrônica: O Que É E Como Funciona Esse Sistema
- Dissident Bicycles : Ai Weiwei’S ‚Forever‘
- Diät Chords By Beatrice Egli @ Ultimate-Guitar.Com
- Divorcio Notarial: Qué Es, Requisitos Y Precio
- Disk Overload Since Utorrent 2.2.1
- Diskussion Zu Tui , Mein Schiff Relax: Tui Cruises‘ neuer Kreuzer sorgt für Diskussionen
- Diskusfische Diskusbuntbarsch , Diskusfische: Aquaristik-Ratgeber
- Disparities In Early-Onset Colorectal Cancer
- Diätetik: Hülsenfrüchte Für Diabetiker Interessant
- Disney Mickey Mouse Fashion Kinderkoffer, Blau, 50 X 39 X
- Djatschenko, G. , Frauenarzt : Frauenärztin Silvia Belzer
- Distance From United States To Iran