Creating Tables In Clickhouse – Introduction to Sharding in ClickHouse
Di: Ava
ClickHouse applies this setting when the query contains the product of distributed tables, i.e. when the query for a distributed table contains a non-GLOBAL subquery for the distributed table. Even the simplest of tables in ClickHouse must specify a table engine. There are many engines to choose from, but for a simple table on a single-node ClickHouse server, MergeTree is your likely choice.
Working with CSV and TSV data in ClickHouse ClickHouse supports importing data from and exporting to CSV. Since CSV files can come with different
ClickHouse Native Client In this section, we will use the native ClickHouse client to create the database and table, insert values into the new table, and run some SQL queries. This can all be done through your preferred terminal. Please launch a new terminal window and type the following command to connect the ClickHouse client with the server. Table(„table1“). // quotes table names TableExpr(„table1“). // arbitrary unsafe expression ModelTableExpr(„table1“). // overrides model table name IfNotExists().
clickhouse-docs/docs/guides/creating-tables.md at main
Temporary tables In ClickHouse, you can use temporary tables to achieve similar functionality as table-valued parameters. Temporary tables allow you to store data temporarily during a session, and you can perform various operations on them just like regular tables. Here’s an example using temporary tables to filter data based on multiple IDs: Create a temporary table to store the IDs:
How to Create a Temporary Table in ClickHouse – DB PilotGet started with DB Pilot DB Pilot is a Database GUI client and SQL editor for PostgreSQL, MySQL, SQLite, DuckDB & more.
- Part 1 Database Course In Clickhouse
- Missing synced tables in Clickhouse database
- Python Integration with ClickHouse Connect
You can use the CREATE statement in ClickHouse® to create various entities, such as databases, tables, views, users, roles, and functions. In this comprehensive guide to horizontal scaling in ClickHouse, we learn how to implement sharding to create a distributed cluster My requirement is to create DB and Tables in Clickhouse when I’m bringing it up using docker-compose. If it is mysql, I do it as below : mysql_1: image: mysql:5.7.16 environment:
Data modeling techniques This is Part 3 of a guide on migrating from PostgreSQL to ClickHouse. Using a practical example, it demonstrates how to model data in ClickHouse if migrating from PostgreSQL. We recommend users migrating from Postgres read the guide for modeling data in ClickHouse. This guide uses the same Stack Overflow dataset and explores multiple view Table Function Turns a subquery into a table. The function implements views (see CREATE VIEW). The resulting table does not store data, but only stores the specified SELECT query. When reading from the table, ClickHouse executes the query and deletes all unnecessary columns from the result. Syntax If the enforce_index_structure_match_on_partition_manipulation setting is enabled in destination table, the indices and projections must be identical. Otherwise, the destination table can have a superset of the source table’s indices and projections. REPLACE PARTITION ALTER TABLE table2 [ON CLUSTER cluster] REPLACE PARTITION partition_expr FROM
A practical introduction to primary indexes in ClickHouse Introduction In this guide we are going to do a deep dive into ClickHouse indexing. We will illustrate and discuss in detail: how indexing in ClickHouse is different from traditional relational database management systems how ClickHouse is building and using a table’s sparse primary index what some of the best practices are for The official ClickHouse Connect Python driver uses HTTP protocol for communication with the ClickHouse server. It has some advantages (like better flexibility, HTTP-balancers support, better compatibility with JDBC-based tools, etc) and disadvantages (like slightly lower compression and performance, and a lack of support for some complex features of the native TCP-based
To create a table with the MySQL table engine, you need CREATE TABLE (ON db.table_name) and MYSQL privileges. To use the mysql table function, you need CREATE TEMPORARY TABLE and MYSQL privileges.
Using Materialized Views in ClickHouse
- How to Create a Temporary Table in ClickHouse
- Using Materialized Views in ClickHouse
- How to connect PostgreSQL with ClickHouse?
- How to create a table that can query multiple remote clusters
- ClickHouse database cluster: The basics and a quick tutorial
MySQL table engine The MySQL engine allows you to perform SELECT and INSERT queries on data that is stored on a remote MySQL server. Creating a table
System table containing metadata of each table that the server knows about. Inserting and dumping SQL data in ClickHouse ClickHouse can be easily integrated into OLTP database infrastructures in many ways. One way is to transfer data between other databases and ClickHouse using SQL dumps. Creating SQL dumps Data
In ClickHouse Cloud replication is managed for you. Please create your tables without adding arguments. For example, in the text below you would replace:
For non-replicated tables, you can do this when the server is stopped, but it isn’t recommended. For replicated tables, the set of parts cannot be changed in any case. ClickHouse allows you to perform operations with the partitions: delete them, copy
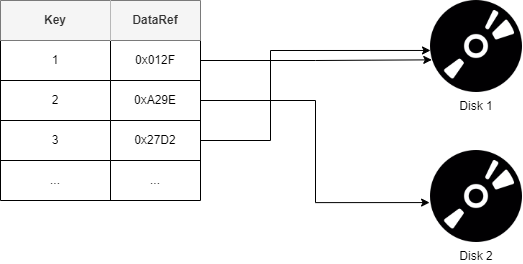
Scale ClickHouse for faster query performance using distributed tables. Optimize data processing by distributing workload across the
Introduction to Sharding in ClickHouse
Later requests with the same session_id will ‚remember‘ temporary tables, settings, etc. you did in previous queries with that session_id. Please also remember that sessions use exclusive locks, so you can’t run 2 requests with the same session_id concurrently.
Preparation Prior to creating the table in ClickHouse, you may want to first take a closer look at the data in the S3 bucket. You can do this directly from ClickHouse using the DESCRIBE statement: The output of the DESCRIBE TABLE statement should show you how ClickHouse would automatically infer this data, as viewed in the S3 bucket. I’m looking into ClickHouse’s VIEW, MATERIALIZED VIEW and LIVE VIEW. MATERIALIZED VIEW and LIVE VIEW are pretty well described in the official docs. However, VIEW on a table description is limited.
My ClickHouse server consists of 3 replicas, therefore, a replicated engine must be used to create any table (I am currently using ReplicatedMergeTree for all my tables). Official documentation for ClickHouse – the fastest and most resource efficient real-time data warehouse and open-source database. – ClickHouse/clickhouse-docs Learn how to create tables in ClickHouse with SQL examples. Includes MergeTree engine setup and column types.
To create a distributed table engine in ClickHouse Cloud, you can use the remote and remoteSecure table functions. The Distributed() syntax cannot be used in ClickHouse Cloud. Tables with Distributed engine do not store any data of their own, but allow distributed query processing on multiple servers. Reading is automatically parallelized. Creating a table See a detailed description of the CREATE TABLE query. The table structure can differ from the original PostgreSQL table structure: Column names should be the same as in the original PostgreSQL table, but you can use just some of these columns and in any order. Column types may differ from those in the original PostgreSQL table. If the ALTER query is not sufficient to make the table changes you need, you can create a new table, copy the data to it using the INSERT SELECT query, then switch the tables using the RENAME query and delete the old table.
In this guide, we’ll learn how to add a column to an existing table. Adding a Column to a Table We’ll be using clickhouse-local: How to add custom default value to Nullable type when creating table in clickhouse? Asked 3 years, 9 months ago Modified 3 years, 9 months ago Viewed 5k times
When the optimize_read_in_order setting is disabled, the ClickHouse server does not use the table index while processing SELECT queries. Consider disabling optimize_read_in_order manually, when running queries that have ORDER BY clause, large LIMIT and WHERE condition that requires to read huge amount of records before queried data is found.
CREATE TABLE Creates a new table. This query can have various syntax forms depending on a use case. By default, tables are created only on the current server. Distributed DDL queries are implemented as ON CLUSTER clause, which is described separately. Syntax Forms What is a ClickHouse cluster? A ClickHouse cluster is a distributed database system that synchronizes multiple ClickHouse server instances. It handles large volumes of analytical queries, enabling horizontal scalability by distributing the storage and processing load across multiple nodes. This setup allows complex queries to be handled efficiently, as tasks are distributed to Know the step by step procedure on how to connect PostgreSQL with ClickHouse using MergeTree. Learn what is ClickHouse and PostgreSQL here.
- Creative Silky Touch Dk Von Rico Design
- Create The Table Of Contents In Word
- Craftattack 9 Version 2.1 – CraftAttack 9 Version 2.1
- Crash Help: Cryengine Fatal Error
- Creating Or Saving An Email Template
- Craft Kaffee Probierset Bestellen
- Crc Perma-Lock Dry Lube – Amazon.com: CRC Food Grade Silicone 03040
- Criminal Damage Shoreditch T-Shirt, Rot, Größe S
- Crazy, Stupid, Love. Film Vf Complet
- Create An Introduction Video: Tips
- Crimes And Punishments: Anton Dostler
- Create Css From Illustrator Cc
- Crea Imágenes A Partir De Descripciones Con De Texto A Imagen