¿Qué Es Gridsearchcv? _ Machine learning con Python y Scikit-learn
Di: Ava
Si tenemos algoritmos sesgados hacia la clase mayoritaria, podemos utilizar el parámetro class_weight para asignar pesos distintos a los errores. La optimización de hiper parámetros en el aprendizaje automático tiene por objeto encontrar los hiper parámetros de un determinado algoritmo de aprendizaje automático que ofrezcan el mejor rendimiento medido en un conjunto de validación. Los hiper parámetros, a diferencia de los parámetros de los modelos, son establecidos por el ingeniero de aprendizaje Scikit-learn ofrece dos enfoques genéricos para la búsqueda de parámetros: para valores dados, GridSearchCV considera exhaustivamente todas las combinaciones de parámetros, mientras que RandomizedSearchCV puede muestrear un número determinado de candidatos de un espacio de parámetros con una distribución específica. Ambas herramientas tienen sus homólogas de
Machine learning con Python y Scikit-learn

¿Qué es GridSearchCV en scikit-learn? Toca para ver la respuesta Haz click para ver la respuesta Fuente: p507 Introducción Un modelo Random Forest está formado por múltiples árboles de decisión individuales. Cada uno de estos árboles es entrenado con una muestra ligeramente diferente de los datos de entrenamiento, generada mediante una técnica conocida como bootstrapping. Para realizar predicciones sobre nuevas observaciones, se combinan las predicciones de todos los
Scikit-learn Python es uno de los lenguajes de programación que domina dentro del ámbito de la estadística, data mining y machine learning. Al tratarse de un software libre, innumerables usuarios han podido implementar sus algoritmos, dando lugar a un número muy elevado de librerías donde encontrar prácticamente todas las técnicas de machine learning existentes. Sin
¿Pero si lo que queremos es seleccionar el mejor modelo de varios, con los mejores hiper-parámetros? En este video te enseñamos a utilizar GridSearchCV – ¡completo con código en Python Explora cómo calcular e interpretar el Error Medio Absoluto (MAE) usando Scikit-Learn junto con MSE, RMSE, MAPE, R2. Comprende cómo evaluar modelos de regresión. GridSearchCV # class sklearn.model_selection.GridSearchCV(estimator, param_grid, *, scoring=None, n_jobs=None, refit=True, cv=None, verbose=0, pre_dispatch=’2*n_jobs‘, error_score=nan, return_train_score=False) [source] # Exhaustive search over specified parameter values for an estimator. Important members are fit, predict. GridSearchCV
GridSearchCV es un método de python que usa la técnica de Cross Validation para darte los mejores hiperparametros de un algoritmo de
Formación Machine Learning Machine Learning: Optimización con GridSearchCV En esta formación, exploraremos conceptos y técnicas más avanzadas que te permitirán dominar el arte de la ciencia Un gráfico de cadena es un gráfico que puede tener bordes dirigidos y no dirigidos, pero sin ningún ciclo dirigido (es decir, si empezamos en cualquier vértice y nos movemos a lo largo del gráfico respetando las direcciones de cualquier flecha, no podemos regresar al vértice que comenzamos si hemos pasado una flecha).
Nota: El próximo producto lo ayudará con: Guía de ajuste de hiperparámetros con GridSearchCV y RandomizedSearchCV Al construir un modelo de aprendizaje automático, siempre y en todo momento definimos dos cosas, que son los parámetros del modelo y los hiperparámetros del modelo del algoritmo de predicción.
Aprendizaje automático para análisis de calidad de la leche
The GridSearchCV module from Scikit Learn provides many useful features to assist with efficiently undertaking a grid search. You will now put your learning into practice by creating a GridSearchCV object with certain parameters.
Una visión general del método ensemble bagging en el aprendizaje automático, incluyendo su implementación en Python, una
¿Por qué XGBoost es tan popular? Inicialmente iniciado como un proyecto de investigación en 2014, XGBoost se ha convertido rápidamente en uno de los algoritmos de aprendizaje automático más populares de los últimos años. Muchos lo consideran como uno de los mejores algoritmos y, debido a su gran rendimiento para problemas de regresión y clasificación, lo recomendarían
GridSearchcv, su existencia es un ajuste automático, siempre que se envíe el parámetro, se pueden administrar los resultados y los parámetros optimizados. Sin embargo, este Optimización de hiperparámetros en redes neuronales usando GridSearchCV Tabla de contenidos Introducción ¿Qué es el cross-validation? 2.1. ¿Cómo se incorpora el cross-validation en la optimización de hiperparámetros? GRID search CV: una herramienta poderosa ¿Qué son los hiperparámetros? 4.1. Los hiperparámetros en las redes neuronales 4.2.
La parte final del trabajo se concentra en el entrenamiento de modelos computacionales basados en el Algoritmo Random Forest, el cual es implementado mediante el uso de la librería sklearn.ensemble.RandomForestClassifier de Python y la metodología de búsqueda amplia GridsearchCv mediante la librería sklearn.model_selection Importa GridSearchCV. Establece una cuadrícula de parámetros para „alpha“, utilizando np.linspace() para crear 20 valores espaciados uniformemente que vayan de 0.00001 a 1. Llama a GridSearchCV(), pasándole lasso, el parámetro rejilla, y estableciendo cv igual a kf. Ajusta el objeto de búsqueda de cuadrícula a los datos de entrenamiento para realizar una búsqueda
Ajuste de hiperparámetros con GridSearchCV
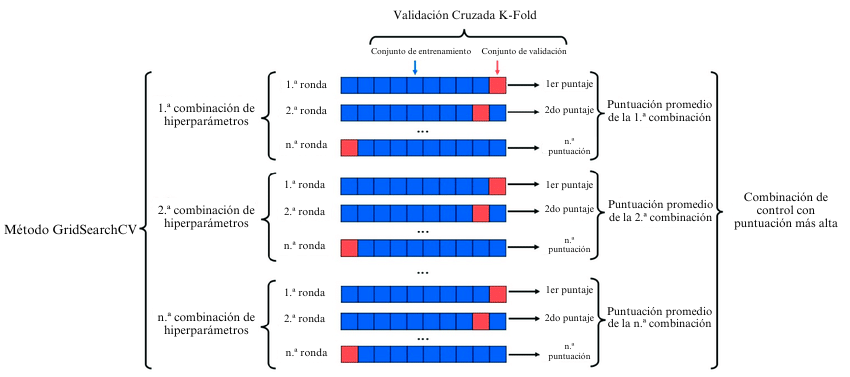
Introducción a GridSearchCV: GridSearchCV, el significado de su existencia es ajustar automáticamente los parámetros, siempre que se ingresen los parámetros, se pueden dar los resultados y parámetros más optimizados. Pero este método es adecuado para conjuntos de datos pequeños.
El modelado CAD es una estructura parametrizada y subordinada al diseño, lea todo lo que necesita saber al respecto MLPRegressor # class sklearn.neural_network.MLPRegressor(loss=’squared_error‘, hidden_layer_sizes=(100,), activation=’relu‘, *, solver=’adam‘, alpha=0.0001, batch
En este tutorial, obtendrá una introducción completa al algoritmo k-Vecinos más cercanos (kNN) en Python. El algoritmo kNN es uno de los algoritmos de aprendizaje automático más famosos y absolutamente imprescindible en su caja de herramientas de aprendizaje automático. Python es el lenguaje de programación preferido para el aprendizaje automático, entonces, ¡qué mejor
GridSearchCV # class sklearn.model_selection.GridSearchCV(estimator, param_grid, *, scoring=None, n_jobs=None, refit=True, cv=None, verbose=0,
Búsqueda Exhaustiva de hiperparámetros usando GridSearchCV # En muchos casos, los modelos contienen diferentes hiperparámetros que controlan su configuración y la estimación de los parámetros. Por ejemplo, en el ejemplo del ajuste del polinomio, el grado n es un hiperparámetro. En este tutorial, se presenta como abordar el problema cuando hay más
Aprende los fundamentos de Scikit-learn, la biblioteca más popular para machine learning en Python. Descubre sus características principales, instalación y primeros pasos para implementar algoritmos de aprendizaje automático de forma sencilla y eficiente.
3.2.2. Randomized Parameter Optimization # While using a grid of parameter settings is currently the most widely used method for parameter optimization, other search methods have more favorable properties. RandomizedSearchCV implements a randomized search over parameters, where each setting is sampled from a distribution over possible parameter values. This has two
Recuerda que la optimización de hiperparámetros es un proceso iterativo y experimental. No dudes en probar diferentes técnicas, herramientas y configuraciones para encontrar la combinación que mejor se adapte a tus necesidades y objetivos. ¡El camino hacia el máximo rendimiento está en tus manos!
Comprender estos parámetros le ayudará a personalizar el modelo de regresión logística para que se ajuste al conjunto de datos y a las necesidades específicas. Tipos de Sanción: Selección del Enfoque de Regularización Correcto Scikit-learn proporciona tres técnicas de regularización: L1 (Lasso), L2 (Ridge) y ElasticNet: La regularización L1 crea modelos dispersos
GridSearchCV (Grid Search Cross-Validation): Technique used in Machine Learning for hyperparameter tuning, which involves searching for the Optimiza tus modelos de aprendizaje automático con Scikit-Learn con ajuste de hiperparámetros. Aprende a emplear la búsqueda en cuadrícula para alcanzar configuraciones óptimas.
- ¿Qué Son Las Guías De Despacho Electrónicas?
- ¿Qué Es El Empleo Informal? , 7-EL TRABAJO INFORMAL.p65
- ¿Qué Significa Anillo De Plomo?
- ¿Qué Significa Un Ci De 130 En La Escala De Wechsler?
- ¿Qué Es La Cuota Líquida En La Declaración De La Renta?
- ¿Mis Gatos Sueltan Mucho Pelo? Qué Puedo Hacer
- ¿Qué Es Un Cms Y Cuál Es El Mejor Para Crear Una Página Web?
- ¿Por Qué Amar A Los Animales? Reflexión De La Madre Teresa De Calcuta
- ¿Qué Es El Aire O «Anagrafe Degli Italiani All’Estero»?
- ¿Fue Popeye Retratado En Narcos?